

01
Problem
Two sides of the same workflow break.
Business problem
Onboarding new enterprise tenants stalls because admins arrive with hundreds of legacy PDF and paper checklists. Manual digitization is the single biggest source of implementation friction and a leading driver of stalled rollouts.
User problem
Site safety managers and compliance admins re-key checklists by hand into the platform. Field types are inconsistent, safety-critical wording gets paraphrased away, and an inspection program that should launch in a week takes a month.
02
Before / after workflow
Same job, different surface area.
- Paper or PDF checklist arrives from site team
- Admin re-keys questions into the platform manually
- Inconsistent response types, missed required fields
- Inspection setup delayed by days or weeks
- Upload PDF or photo of checklist
- OCR extracts text + layout, LLM structures questions
- Human reviews flagged fields, accepts or edits
- Digital checklist scheduled and assigned the same day
03
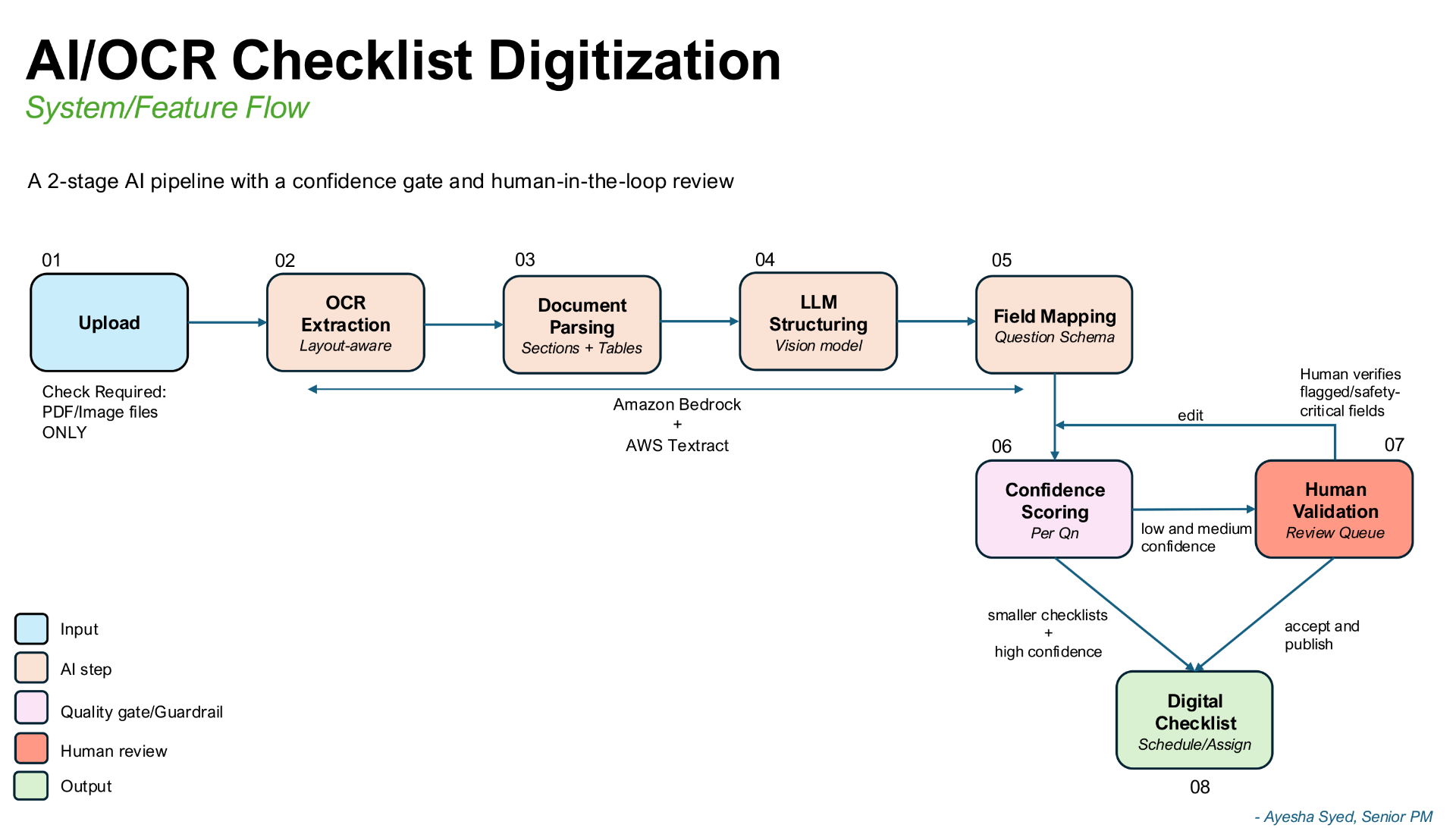
System flow
Two-stage pipeline with a human in the middle.
04
My PM role & product decisions
My PM role
End-to-end owner
- Problem framing + opportunity sizing with implementation team
- Vendor and model trade-off analysis (OCR vs custom ML vs managed multimodal)
- PRD, UX flow with design, eval criteria, rollout plan
- Customer-council validation and adoption playbook
Product decisions
Why managed multimodal + HITL
- Managed multimodal: ship sooner, no in-house model maintenance
- Two-stage pipeline: layout-aware OCR feeds vision LLM for structure
- Confidence-scored review queue instead of autonomous publish
- Map output into existing checklist schema, not a parallel data model
05
PRD excerpt
- User
- Site safety manager / compliance admin onboarding a new inspection program.
- Problem
- Manual checklist digitization is slow, inconsistent, and error-prone — and blocks tenant onboarding.
- Goal
- Reduce setup time per checklist and improve structural quality of the digital output.
- Non-goal
- Fully autonomous publishing without human review of safety-critical content.
- Success metrics
- Extraction accuracy (field-level F1)
- Time-to-publish per checklist (target: < 10 min, baseline: hours)
- Review acceptance rate without edits
- Rework rate after publish
- Time-to-first-inspection for a new tenant
06
Trust, safety & quality gates
Every extraction passes through gated checks before it reaches the user.
| Gate | What it checks | Pass criteria | Human fallback |
|---|---|---|---|
OCR confidence | Per-block recognition confidence from the OCR engine | ≥ 0.85 average; ≥ 0.70 per safety-critical block | Flag block for manual transcription in review queue |
Question extraction completeness | Number of detected questions vs. layout-implied count | Detected ≥ 95% of expected questions | Show side-by-side comparison; admin adds missing items |
Response type classification | Yes/No, numeric, text, date, photo, signature mapping | Model confidence ≥ 0.8 AND matches expected pattern | Default to text + surface suggested type for confirmation |
Duplicate question detection | Semantic similarity across extracted questions | No two questions within similarity threshold of each other | Highlight duplicates and prompt admin to merge or keep |
Required field validation | Owner, frequency, response type, scoring rule presence | All required metadata populated | Block publish; route to admin to complete missing fields |
Safety-critical wording preservation | Regulated phrases preserved verbatim, not paraphrased | Exact-match against protected terminology dictionary | Force original-wording mode; require explicit override |
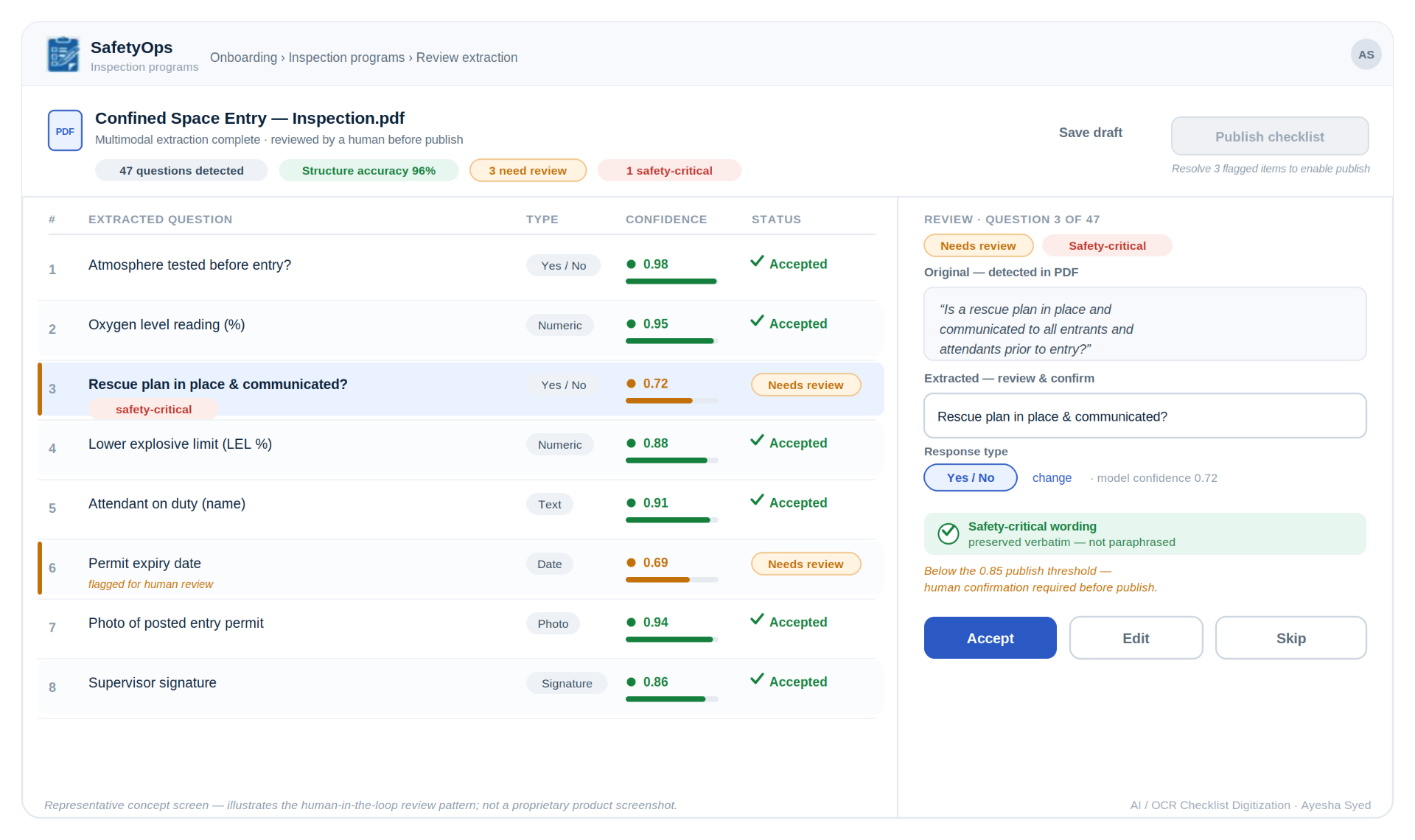
The review experience
Flagged and safety-critical fields route to a confidence-scored review queue before anything publishes.
07
Sample evaluation framework
Three dimensions we score offline and in production.
Eval 01
Structure accuracy
Eval 02
Field classification
Eval 03
Safety integrity
08
Tradeoffs, outcome, next
Tradeoffs
What we deliberately accepted
- Shipped on managed multimodal instead of a custom-trained model — faster to value, modest accuracy ceiling
- Kept human review in the loop instead of pursuing autonomous publish
- Mapped into existing schema, deferring a richer checklist data model
Outcome
What changed
- Checklist setup dropped from hours to minutes per checklist
- Removed the single largest implementation barrier for new tenants
- Repeatable pattern for embedding multimodal AI in existing config flows
What I'd improve next
Next bets
- Confidence-prioritized review queue to focus admin attention
- Feedback loop: capture review edits to improve few-shot prompts
- Extend pattern to JSAs, permits, and audit checklists